스스로 학습하는 초해상화 기술
다양한 분야에서의 활용도가 높아질 것
영상은 타임머신이다. 영상을 통해 경험해보지 못한 1920년대의 서울 거리를 거닐 수 있고, 다시 만날 수 없는 사람의 얼굴을 마주하기도 한다. 그 영상이 훼손되면 과거를 엿볼 수 있는 생생한 통로가 막힌다. 그러나 실망은 금물, 타임머신의 정비공 역시 존재한다. 바로 영상복원 기술이다. 온전하고 정확한 영상복원을 위한 노력은 계속되고 있다.
영상복원, 사각지대를 없애다
영상복원은 손상돼 볼 수 없는 영상부터 화질이 낮아 내용을 알아보기 어려운 영상까지 폭넓은 범위를 대상으로 한다. 이러한 영상들은 복원을 거치면 우리가 보지 못했던 과거를 수면 위로 드러낸다. 따라서 영상복원 기술은 영상 자료가 지닌 역사적 가치를 높이는 데 기여한다. KBS는 재작년 광복절을 맞아 1944년 당시 '일본군' 위안부의 영상을 컬러로 복원해 공개했다. 인터넷에서는 검색 한 번이면 1920년대부터 1990년대까지의 한국을 영상으로 만나볼 수 있다. 모두 영상복원의 결과물이다. 영상복원 기술은 범죄 수사에도 활용된다. 국립과학수사연구원에서는 해당 기술로 블랙박스나 CCTV 영상을 복원해 결정적인 증거를 발견하기도 했다. 과거에는 사람이 한 장면씩 수작업으로 영상을 복원했지만, 현재는 *딥러닝을 활용해 영상을 자동으로 복원하기도 한다.
합성곱 신경망으로 바라본 이미지
우리가 보는 이미지는 수많은 *픽셀로 이뤄져 있다. 특히 컬러 이미지의 경우 각 픽셀은 R(빨강), G(초록), B(파랑)의 세 실수로 표현되기 때문에 이미지는 3차원 데이터로 인식된다. 영상복원에서는 이미지의 특징을 추출하는 과정이 필수적이다. 이때 사용되는 것이 합성곱 신경망, CNN이다. 합성곱 신경망은 두 함수를 서로 곱해서 합하는 합성곱 연산을 사용한다. 즉 원래의 이미지가 첫 번째 함수라면 두 번째 함수는 이미지의 픽셀에 가중치를 부여해 이미지를 변환시키는 ‘필터’의 역할을 한다. 따라서 합성곱 연산을 거치면 주어진 이미지에 필터를 씌워 가중치가 반영된 새로운 이미지를 만들어낼 수 있는 것이다. CNN은 이러한 합성곱 연산을 이용해 이미지에 일정 넓이의 필터를 적용함으로써 해당 부분의 특징들, 나아가 인접 영역과의 연관성까지 반영된 특징들을 추출할 수 있다. 특히 CNN은 여러 개의 필터를 사용하기 때문에 3차원 이미지 데이터도 원활히 다룰 수 있어 저해상도의 이미지나 영상을 고해상도로 변환하는 초해상화 기술에 사용된다. 우리 학교 경영학과 권건우 교수는 “CNN은 간단한 구조지만 정확도가 높다”며 “CNN을 이용하면 이미지를 구성하는 픽셀들을 원활하게 처리해 고해상도 이미지를 얻을 수 있다”고 밝혔다.
CNN을 활용한 초해상화 기술은 영상 재생 기기와 콘텐츠 간의 해상도 격차를 좁힐 수 있다. 현재 우리나라에서는 *8K 디스플레이 등 고화질의 영상을 재생할 수 있는 기기를 흔히 찾아볼 수 있지만 정작 고화질 영상콘텐츠가 부족한 상황이다. 권 교수는 “만약 기기에서 자체적으로 콘텐츠의 화질을 높일 수 있다면 보다 다양한 콘텐츠를 고화질로 이용할 수 있다”며 “이때 사용될 수 있는 기술이 바로 초해상화 기술”이라고 밝혔다.
SRCNN과 VDSR, 학습을 통해 초해상화 기술을 구현하다
초해상화 기술의 구현을 위해서는 우선 여러 개의 CNN으로 네트워크를 구성해야 한다. 이때 CNN은 ‘층’으로 기능하며 입력된 데이터는 각 층을 거치게 된다. 이런 구조를 토대로 구현된 네트워크가 바로 SRCNN(Super Resolution Convolutional Neural Networks)이다. SRCNN에 입력된 저해상도 이미지는 세 개의 층을 거치며 고해상도 이미지로 변환된다. 첫 번째 층에서는 입력받은 이미지의 특징을 추출해 이를 기록한 지도를 만든다. 이후 두 번째 층에서 해당 지도에 합성곱 연산을 적용해 새로운 지도를 제작한다. 두 번째 층의 지도를 기반으로 고해상도 이미지를 재구성하는 과정이 마지막 층에서 이뤄진다. 그러나 SRCNN은 층의 개수가 적어 좁은 영역에서의 특징만 인식할 수 있으며 특정 크기의 영상만을 복원한다는 한계를 가진다.
이러한 SRCNN의 한계를 극복하기 위해 고안된 네트워크가 VDSR이다. VDSR은 20개의 층으로 이뤄져 합성곱 연산이 여러 번 반복되기 때문에 SRCNN보다 원본 이미지와 유사한 특징들을 정확하게 선별해 추출할 수 있다. 또한 VDSR은 잔여학습을 거치며 이미지를 신속하게 처리할 수 있다는 장점을 가지고 있다. 잔여학습이란 기존 이미지와 각 층에서 출력되는 고해상도 이미지 간의 차이를 중심으로 학습하는 것을 말한다. 이 차이를 줄여나가는 방향으로 층을 거치며 학습을 반복하다 마지막에 기존 이미지를 더해준다. 즉 줄여나간 차이에 기존 이미지를 덧씌우는 방식으로 최종 이미지를 만들어내는 것이다. 이런 과정은 모든 계산마다 이미지 전체를 처리해야 하는 SRCNN보다 더 빠르게 계산을 완료할 수 있도록 한다.
모든 크기에서 다양한 정보를 제공하다
현재 초해상화 기술은 높은 화질의 영상이 요구되는 분야라면 어디든지 다양하게 사용되고 있다. 의료영상은 초해상화 기술을 활용하는 대표적 예시다. 의료 분야에서는 신체 조직의 움직임을 영상으로 확인하며 각 조직이 기능을 원활히 수행하고 있는지 판단한다. 우리 학교 글로벌바이오메디컬공학과 박재석 교수는 “영상의 해상도가 낮으면 영상에서 얻을 수 있는 정보의 양이 줄어든다”며 “초해상화 기술을 이용해 고화질의 영상을 얻을 수 있어 질병 진단의 정확도를 높일 수 있다”고 밝혔다.
픽사 애니메이션 스튜디오(이하 픽사)에서는 애니메이션 *렌더링 과정에서의 비용과 시간을 줄이기 위해 초해상화 기술을 사용했다. 화질을 낮춘 상태에서 영상의 렌더링을 끝낸 후 초해상화 기술로 화질을 다시 높임으로써 픽사는 약 60%의 비용을 절감할 수 있었다. 권 교수는 “초해상화 기술의 학습 과정에서 빅데이터를 활용한다면 현재보다도 더 정확하고 활용도 높은 기술로 거듭날 것”이라며 “더 나아가 기술 자체도 여러 가지 딥러닝 모델이 융합되는 형태로 발전하고 있어 성능 향상을 기대해도 좋다”는 의견을 밝혔다.
◆딥러닝=예시 데이터에서 일반화된 규칙을 도출하는 머신러닝의 한 분야.
◆픽셀=디스플레이를 구성하는 최소 단위.
◆8K=이미지나 디스플레이의 너비가 약 8000픽셀인 해상도로, 숫자가 클수록 높은 화질을 의미.
◆렌더링=컴퓨터 그래픽이나 디지털 애니메이션에서 가상으로 완성된 결과를 만들어내는 과정.

ⓒ백년전TV 유튜브 캡처
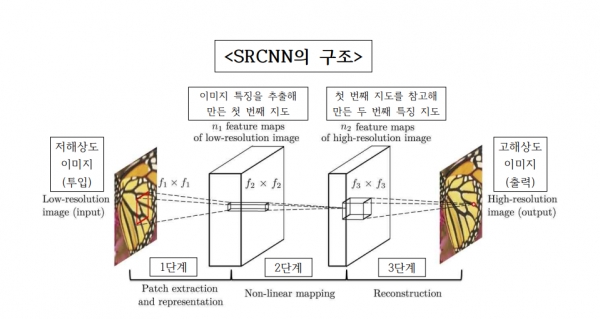
자료: Accurate Image Super-Resolution Using Very Deep Convolutional Networks
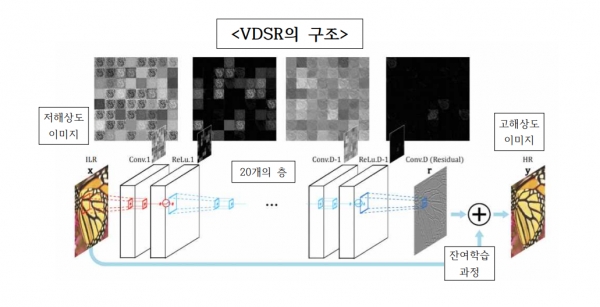
자료: Accurate Image Super-Resolution Using Very Deep Convolutional Networks